Imbalanced data¶
Resampling technique¶
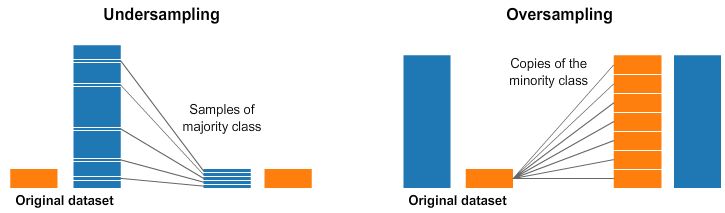
Undersampling¶
Fixed under-sampling¶
Random Under-sampling¶
- Trích xuất các quan sát ngẫu nhiên của lớp đa số cho đến khi đạt được một tỷ lệ cân bằng nhất định. Kỹ thuật này rất là đơn giản, không có bất kỳ giả định nào về dữ liệu
- Tuy nhiên, loại bỏ các quan sát khỏi lớp đa số, chúng ta đang loại bỏ những quan sát quan trọng, và khiến mô hình của chúng ta khó phân biệt các lớp hơn.
Code
# import library
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=42, replacement=True)# fit predictor and target variable
x_rus, y_rus = rus.fit_resample(x, y)
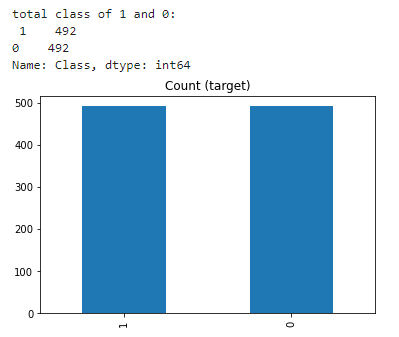
print('original dataset shape:', Counter(y))
print('Resample dataset shape', Counter(y_rus))
Dữ liệu ban đầu:
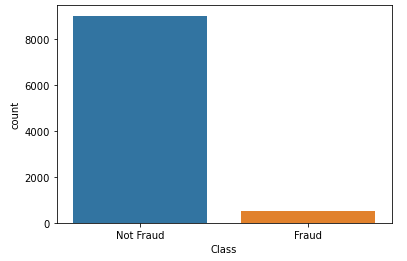
Sau khi randomundersampler:
NearMiss¶
- Ỷ tưởng cơ bản là nó giữ lại nhưng quan sát gần hơn với các lớp thiếu số.
- NearMiss được thiết kế để làm việc các tập dữ liệu văn bản, trong đó mỗi từ được biểu diễn phức tạp.
#import thư viện
from imblearn.under_sampling import NearMiss
nm1 = NearMiss(
sampling_strategy='auto', # chỉ undersample lớp đa số
version=1,
n_neighbors=3,
n_jobs=4) # có 4 core trong máy
X_resampled, y_resampled = nm1.fit_resample(X, y)
Vẽ 2 biến (VarA,VarB) ban đầu:

Sau khi NearMiss:

Instance Hardness¶
- Là một phép đo độ khó để phân loại trường hơp hoặc quan sát một cách chính xác.
- Instance hardness(Xác xuất phân loại sai): một quan sát thuộc 2 điều
- Thuật toán dùng để mô hình hóa nhiệm vụ
- Mối quan hệ quan sát với các quan sát trong tập dữ liệu
- Phép đo instance hardness bằng một trừ đi xác xuất của lớp đa số, thể hiện của một quan sát bị phân loại sai
Code
# import library
from imblearn.under_sampling import InstanceHardnessThreshold
from sklearn.ensemble import RandomForestClassifier
tf = RandomForestClassifier(n_estimators=100, random_state=39, max_depth=3, n_jobs=4)
iht = InstanceHardnessThreshold(estimator = tf, sampling_strategy = 'auto',random_state = 0)
x_resampled, y_resampled = iht.fit_resample(x, y)
print('original dataset shape:', Counter(y))
print('Resample dataset shape', Counter(y_rus))
Trước khi InstancerHardness

Sau khi InstancerHardness

Clean under-sampling¶
Tomek links¶
Nếu 2 mẫu trong tập dữ liệu là nearest neighbour của nhau và từ các lớp khác nhau thì chúng là các tomek link. Vậy nếu một quan sát của lớp đa số trong giống với một quan sát thiếu số thì đó là tomek link.
Tomek's link tồn tại nếu hai mẫu là hàng xóm gần nhất của nhau
Trong quy trình loại bỏ, chúng ta có thể chỉ loại bỏ các mẫu đa số trong các cặp Tomek Link, hoặc loại cả cặp mẫu.
Với Tomek Link, bằng cách loại bỏ nhiễu, chúng ta đang ngăn thuật toán máy học khỏi các trường hợp thực sự khó phân loại, và do đó bằng cách loại bỏ nhiễu, chúng ta có thể cải thiện chất lượng thuật toán.
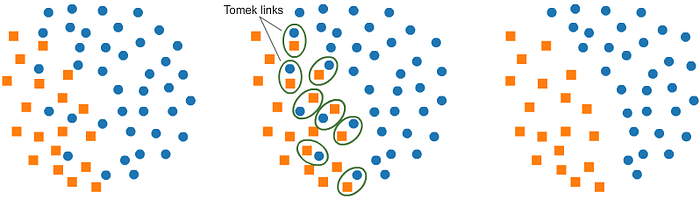
Code
# import library
from imblearn.over_sampling import TomekLinks
tl = TomekLinks(sampling_strategy = "majority")
x_tl,y_tl = tl.fit_resample(X_train,y_train)
print('original dataset shape:', Counter(y_train))
print('Resample dataset shape', Counter(y_tl))
Trước khi tomeklink

Sau khi TomekLink















